
Tech & Innovation
Tech Companies
พักจาก DeepSeek มารู้จัก “Qwen 2.5-Max” โมเดล AI ใหม่ล่าสุดของ Alibaba ที่เคลมว่าฉลาดกว่าทุกด้าน
Date Time: 30 ม.ค. 2568 10:39 น.

“Summary“
โมเดล AI จีนต่อแถวเปิดตัวฉ่ำ ล่าสุด Alibaba ยักษ์ใหญ่อีคอมเมิร์ซจากจีน ส่ง “Qwen 2.5-Max” โมเดลใหม่แข่ง DeepSeek โมเดลจีนต้นทุนต่ำประสิทธิภาพสูงที่กำลังเป็นที่พูดถึงทั่วโลกในขณะนี้ รู้จัก Qwen โมเดลภาษาขนาดใหญ่ (LLM) ที่พัฒนาโดย Alibaba Cloud เพื่อขยายระบบนิเวศ AI ที่กว้างขึ้น
Latest

จับตาคลื่นปัญญาประดิษฐ์จีนที่จะถาโถมหลังจากนี้ เมื่อความสำเร็จของ DeepSeek โมเดลจีนต้นทุนต่ำประสิทธิภาพสูงที่กำลังเป็นที่พูดถึงทั่วโลกในขณะนี้ไม่เพียงสร้างความกังวลให้ตะวันตกแต่ยังทำให้บรรดาคู่แข่งในประเทศดิ้นรนอัปเกรดโมเดลของตนเอง
ล่าสุด Alibaba หนึ่งในบริษัทเทคโนโลยีที่ใหญ่ที่สุดของจีนที่มีชื่อเสียงในด้านแพลตฟอร์มอีคอมเมิร์ซ รวมถึงคลาวด์คอมพิวติ้งและ AI เปิดตัว “Qwen 2.5-Max” โมเดลใหม่มาแข่งขัน
บทความที่เกี่ยวข้อง
รู้จัก Qwen 2.5-Max
Qwen 2.5-Max โมเดล AI ที่ออกแบบมาเพื่อแข่งขันกับโมเดลชั้นนำ เช่น GPT-4o, Claude 3.5 Sonnet และ DeepSeek V3 และนับเป็นโมเดลที่ทรงพลังที่สุดของ Alibaba ในปัจจุบัน โดย Qwen คือ โมเดลภาษาขนาดใหญ่ (LLM) เปิดตัวครั้งแรกในปี 2024 โดยพัฒนาขึ้นจาก Alibaba Cloud หรือหน่วยธุรกิจคลาวด์เพื่อขยายระบบนิเวศ AI ของกลุ่มให้กว้างขึ้น
ชื่อ "Qwen" ย่อมาจาก "Tongyi Qianwen" ในภาษาจีน โมเดลเหล่านี้ได้รับการออกแบบมาเพื่อทำงานด้านการใช้ภาษาโดยตรง การสร้างข้อความ และการประมวลผลข้อมูลหลากหลายแบบ ประกอบด้วยโมเดลที่มีขนาดและความสามารถต่างๆ เช่น Qwen-7B, Qwen-14B และ Qwen-72B รวมถึงเวอร์ชันเฉพาะ เช่น Qwen-Chat สำหรับแอปพลิเคชันการสนทนา และ Qwen-VL สำหรับงานภาพ
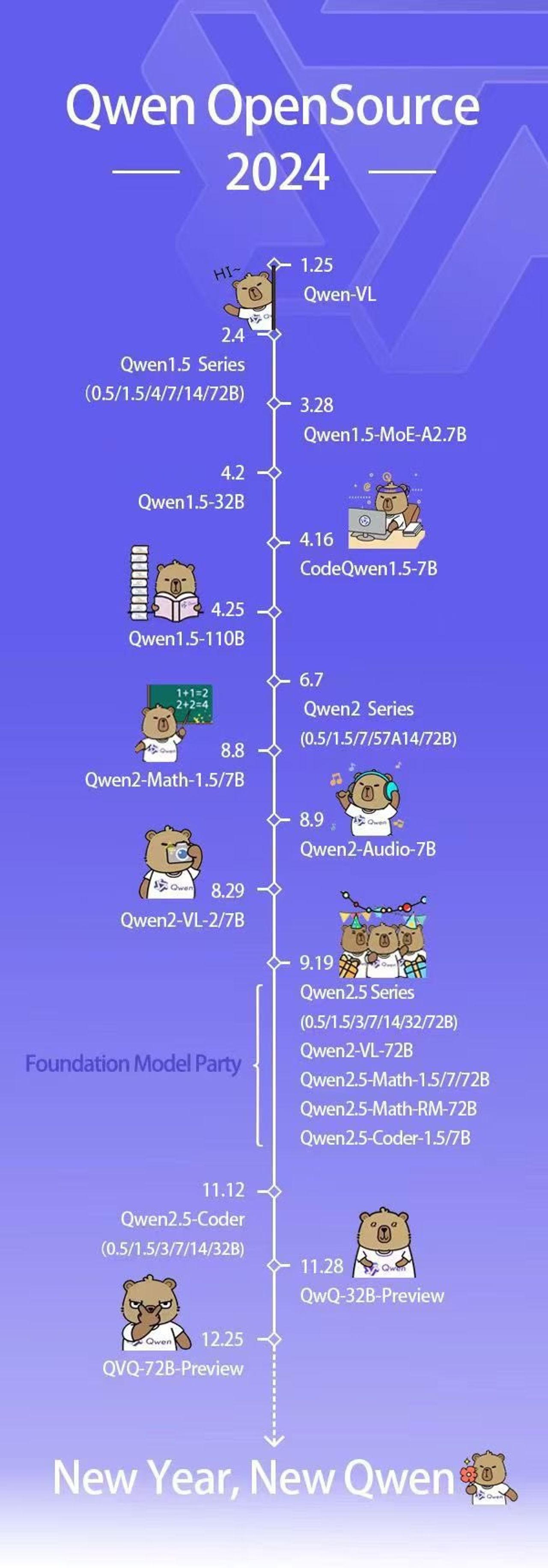
Alibaba เปิดเผยว่า Qwen 2.5-Max ใช้สถาปัตยกรรมแบบ Mixture-of-Experts (MoE) ซึ่งเป็นเทคนิคที่ใช้ใน DeepSeek V3 เช่นกัน ได้รับการฝึกอบรมด้วยโทเค็นมากกว่า 20 ล้านล้านโทเค็น ครอบคลุมหัวข้อ ภาษา และบริบทที่หลากหลาย และถูกนำมาเทรนต่อด้วยวิธี Supervised Fine-Tuning (SFT) และ Reinforcement Learning from Human Feedback (RLHF) ทำให้ Qwen 2.5-Max เป็นอีกหนึ่งโมเดลที่การใช้พลังประมวลผลที่น้อยลงเช่นเดียวกัน
สำหรับจุดเด่นของประสิทธิภาพที่เปิดเผยออกมา Qwen 2.5-Max โดดเด่นทั้งเรื่องความสามารถทั่วไปของ AI โดยความรู้ทั่วไปและความเข้าใจภาษา (MMLU, MMLU-Pro, BBH, C-Eval, CMMU) และผู้นำในเกณฑ์มาตรฐานทั้งหมดในหมวดนี้ รวมถึงการเขียนโค้ดและการแก้ปัญหา (HumanEval, MBPP, CRUX-I, CRUX-O) เช่นเดียวกัน
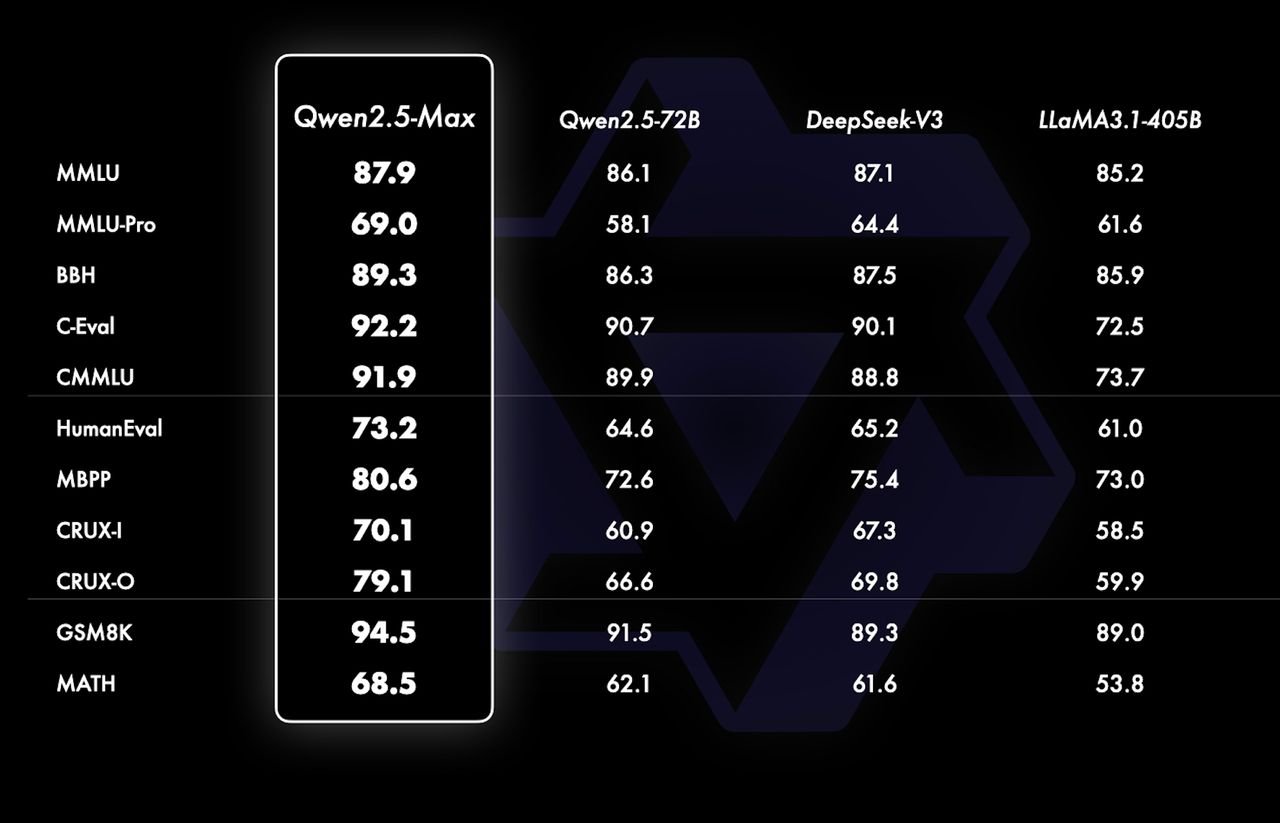
- เกณฑ์มาตรฐาน Arena-Hard ที่ประเมินความชอบของมนุษย์ในคำตอบที่สร้างโดย AI Qwen 2.5-Max ได้คะแนน (89.4) นำหน้า DeepSeek V3 (85.5) และ Claude 3.5 Sonnet (85.2)
- เกณฑ์ Massive Multitask Language Understanding: MMLU-Pro (ความรู้และการใช้เหตุผล) Qwen 2.5-Max ได้คะแนน (76.1) นำหน้า DeepSeek V3 (75.9) เล็กน้อย แต่ยังตามหลัง Claude 3.5 Sonnet (78.0) และรองลงมาอย่าง GPT-4o (77.0) เล็กน้อย
- GPQA-Diamond (เกณฑ์มาตรฐานความรู้ทั่วไป) Qwen 2.5-Max ได้คะแนน (60.1) แซงหน้า DeepSeek V3 (59.1) ในขณะที่ Claude 3.5 Sonnet นำอยู่ที่ (65.0)
- LiveCodeBench (ความสามารถในการเขียนโค้ด) ที่ 38.7 Qwen 2.5-Max อยู่ในระดับเดียวกับ DeepSeek V3 (37.6) แต่ยังตามหลัง Claude 3.5 Sonnet (38.9)
- LiveBench (ความสามารถโดยรวม) Qwen 2.5-Max เป็นผู้นำด้วยคะแนน 62.2 แซงหน้า DeepSeek V3 (60.5) และ Claude 3.5 Sonnet (60.3)
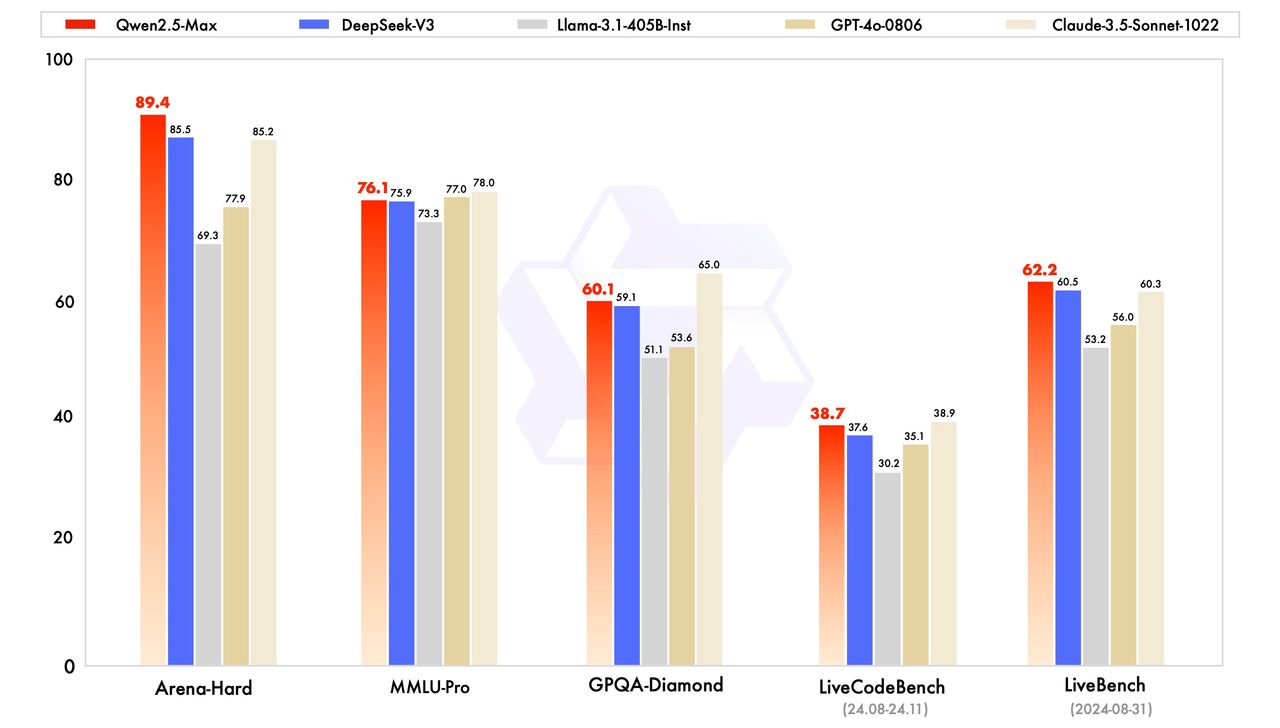
อย่างไรก็ตามโมเดลนี้ไม่ใช่โมเดลการให้เหตุผลเหมือนกับ DeepSeek R1 หรือ o1 ของ OpenAI ซึ่งหมายความว่าโมเดลนี้ไม่ได้แสดงกระบวนการคิดอย่างชัดเจน นอกจากนี้การเปรียบเทียบความสามารถจำกัดอยู่แค่โมเดลเปิด เช่น Qwen 2.5-Max, DeepSeek V3, LLaMA 3.1-405B และ Qwen 2.5-72B เพราะ GPT-4o และ Claude 3.5 Sonnet เป็นโมเดลที่เป็นกรรมสิทธิ์และไม่มีเวอร์ชันพื้นฐานที่เผยแพร่สู่สาธารณะ
ปัจจุบัน Qwen 2.5-Max สามารถเข้าใช้ฟรีผ่านแพลตฟอร์ม Qwen Chat บนเบราว์เซอร์ โดย API ของ Qwen 2.5-Max เปิดให้ใช้งานบน Alibaba Cloud Model Studio

ติดตามเพจ Facebook : Thairath Money ได้ที่ลิงก์นี้ -