
Tech & Innovation
Tech Companies
สรุปความโหดโมเดล “o1” ร่างทอง ChatGPT ที่ OpenAI เพิ่งเปิดตัว เก่งกว่าเดิมอย่างไรบ้าง?
Date Time: 13 ก.ย. 2567 15:15 น.

“Summary“
OpenAI เปิดตัวโมเดล ChatGPT ตัวใหม่ ในชื่อ “o1” หรือเรียกกันภายในว่าโมเดล “Strawberry” ถูกออกแบบมาให้มีการคิดแบบเป็นเหตุเป็นผล “Reasoning Ability” คล้ายกับการคิดแบบมนุษย์มากขึ้น โดยจะใช้เวลาในการวิเคราะห์นานขึ้น และหาคำตอบอย่างเป็นขั้นเป็นตอน
Latest

OpenAI เปิดตัวโมเดล ChatGPT ตัวใหม่ในชื่อ “o1” หรือเรียกกันภายในว่าโมเดล “Strawberry” โดยโมเดลนี้ถูกออกแบบมาให้มีการคิดแบบเป็นเหตุเป็นผล “Reasoning Ability” คล้ายกับการคิดแบบมนุษย์มากขึ้น โดยจะเน้นไปที่การคำนวณ การวิเคราะห์หาคำตอบ และการเขียนโค้ดที่มีประสิทธิภาพมากขึ้น
โมเดล “o1” มีชื่อที่เรียกกันภายในว่า “Strawberry” คาดว่ามาจากประเด็นที่ก่อนหน้านี้มีการตั้งคำถามกับ ChatGPT-4o ว่า “How many ‘r’ in the word ‘Strawberry’?” หรือ “มีตัว r กี่ตัวในคำว่า Strawberry” ซึ่งคำตอบที่ ChatGPT ตอบกลับมาคือ “The word ‘Strawberry’ has two ‘r’s.” หรือ “มี r แค่ 2 ตัวในคำว่า Strawberry” ซึ่งนั่นเป็นคำตอบที่เราคาดไม่ถึง เพราะจริง ๆ แล้วคำตอบคือ “มี r อยู่ 3 ตัว”

โดยโมเดลใหม่ “o1” นี้จะใช้เวลาในการคิดคำตอบนานขึ้น ใช้ภาษาที่มีความเป็นธรรมชาติมากขึ้น และจากรายงานของ OpenAI ชี้ว่า โมเดลนี้ยังสามารถแก้ปัญหาที่ซับซ้อนได้อย่างเป็นขั้นเป็นตอน ซึ่งรวมไปถึงโจทย์คณิตที่ยาก ๆ และเขียนโค้ดให้ซับซ้อนได้ อีกทั้งยังมีการคิดด้วยตรรกะมากกว่าที่จะเรียบเรียงตัวหนังสือออกมาเป็นคำตอบเฉย ๆ
โมเดลใหม่นี้จะเปิดให้ใช้งานบน ChatGPT Plus และบน API โดยผู้ใช้สามารถเลือกได้ว่าจะใช้งาน “o1-preview” หรือ “o1-mini”
ร่างทอง ChatGPT ฉลาดขึ้นอย่างไรบ้าง?
OpenAI ได้มีการทดสอบวัดระดับความสามารถของโมเดล “o1” โดยเทียบกับ “ChatGPT-4o” และในบางประเด็นก็มีการเทียบกับทักษะของมนุษย์ ผ่านการให้ตอบคำถามจากข้อสอบทางวิชาการ ข้อสอบโอลิมปิกคณิตศาสตร์ เขียนโค้ด แก้โจทย์ครอสเวิร์ด ทำข้อสอบภาษาอังกฤษ ไปจนถึงตอบคำถามระดับปริญญาเอก พบว่า
— มีประสิทธิภาพในการแก้โจทย์ปัญหาได้แม่นยำกว่ามนุษย์ —
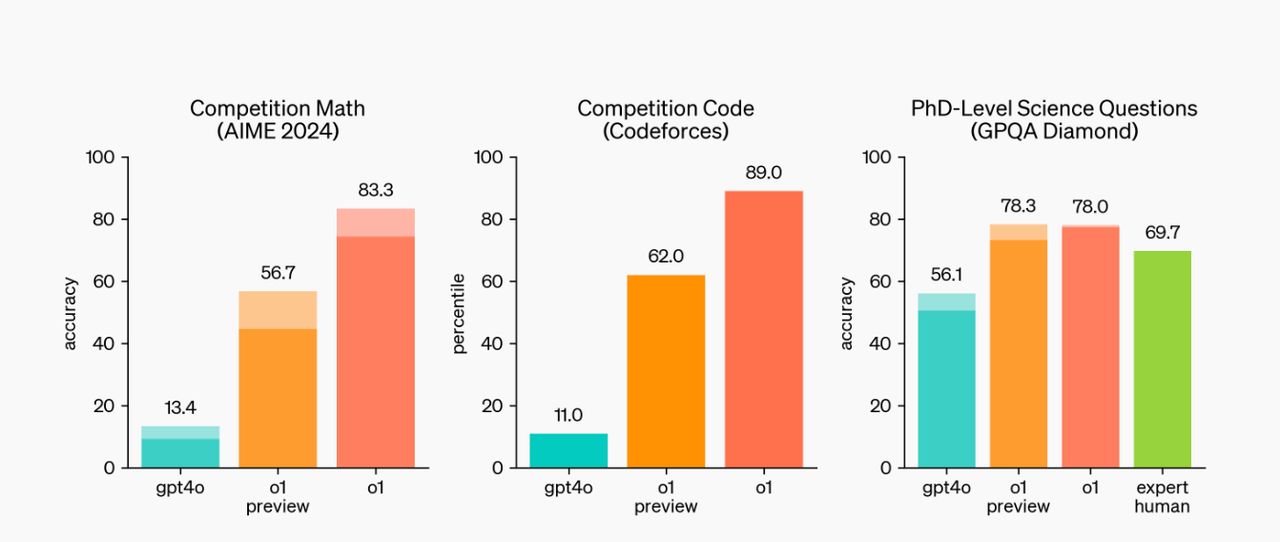
จากการทดสอบวัดระดับ พบว่า โมเดล o1 มีความแม่นยำในการแก้โจทย์ปัญหาคณิตศาสตร์ระดับโอลิมปิกที่ 83.3% (สูงกว่า GPT-4o ที่มีความแม่นยำ 13.4%) มีความแม่นยำในการตอบคำถามทางวิทยาศาสตร์ระดับปริญญาเอกที่ 78% (สูงกว่าโมเดล GPT-4o ที่แม่นยำ 56.1% และยังสูงกว่าผู้เชี่ยวชาญที่มีความแม่นยำที่ 69.7%)
— “Chain of Thought” คิดคำตอบอย่างเป็นวิธี —
ในโมเดล o1 การตอบคำถามของ ChatGPT จะใช้เวลาในการคิดคำนวณนานขึ้น และจะใช้วิธีการที่เรียกว่า “Chain of Thought” ในการแก้ปัญหาที่ซับซ้อนขึ้น และจะมีการขัดเกลาข้อมูลก่อนที่จะสร้างเป็นคำตอบออกมา โมเดลนี้มีการเรียนรู้ที่จะรับรู้และแก้ไขข้อผิดพลาด ด้วยการแยกย่อยชุดคำถาม และวิเคราะห์แบบ Step by Step เพื่อให้คำตอบที่สมเหตุสมผลมากขึ้น อีกทั้งยังสามารถทำงานด้วยวิธีการที่แตกต่างกันไป หากพบว่าวิธีการแรกที่ใช้ไม่สามารถหาคำตอบได้
โดยในตัวอย่างที่เปิดเผยมาโดย OpenAI พบว่า โมเดลนี้สามารถถอดรหัส (Decode) ชุดภาษาหรือโค้ดที่ผู้ถามต้องการได้อย่างเป็นขั้นตอน (ดูตัวอย่างการถอดรหัสได้ที่ OpenAI.com) รวมไปถึงสามารถวิเคราะห์หรือวินิจฉัยโรคตามอาการที่ Prompt ลงไปได้อีกด้วย พร้อมกับให้คำแนะนำว่าต้องทำการรักษาอย่างไรต่อ
— พัฒนาทักษะโปรแกรมมิ่งขั้นสูง เขียนโค้ดได้ดีขึ้น —
ในการเทรนโมเดล o1 ได้มีการประเมินผลในการแก้ปัญหาทางโปรแกรมมิ่งขั้นสูง โดยทดสอบผ่านการแข่งขันในโปรแกรม Codeforces พบว่า โมเดล o1 สามารถทำคะแนน Elo ได้ถึงมากถึง 1807 คะแนน ซึ่งสูงกว่า 93% ของผู้แข่งขันที่เป็นมนุษย์ทั้งหมด
จากวิดีโอที่เผยแพร่บนเว็บไซต์ ถึงการลองทดสอบให้ ChatGPT-o1 สร้างโค้ดออกแบบเกม “Snake” หรือ “งูกินหาง” พบว่า โมเดลนี้ใช้เวลาไม่กี่วินาทีก็สามารถ Generate โค้ดของทั้งเกมออกมาได้ (ดูวิดีโอได้ที่ OpenAI)
— เน้นเรื่องความปลอดภัย —
เนื่องจากโมเดลนี้สามารถคิดและให้คำตอบอย่างเป็นขั้นเป็นตอน ความสามารถนี้ OpenAI มองว่าจะช่วยเสริมเรื่องของความปลอดภัยได้เป็นอย่างดี โมเดลนี้จะสามารถตรวจสอบเนื้อหาได้เป็นอย่างดี โดยมีการทดสอบความปลอดภัยผ่านการจำลองการโจมตีทางไซเบอร์ (Red-Teaming) ก่อนการนำไปใช้งานจริง
นอกจากโมเดล o1 จะให้คำตอบแบบเป็นขั้นเป็นตอนได้แล้ว ผู้ใช้ก็ควรจะ Prompt คำถามหรือชุดข้อมูลที่มีการอธิบายเป็น Step by Step ด้วยเช่นกัน เพื่อให้ได้คำตอบที่ดูสมเหตุสมผลมากที่สุด
หลายฝ่ายมองว่า หลังจากนี้ประสบการณ์ในการใช้งาน ChatGPT ด้วยโมเดลใหม่จะเปลี่ยนไปอย่างสิ้นเชิง ผู้ใช้จะได้เห็นคำตอบที่ดูมีความเป็นธรรมชาติมากขึ้น คล้ายคลึงกับการสื่อสารกับมนุษย์ด้วยกัน ไม่ได้ตอบคำถามด้วย “ข้อมูล” ที่รวบรวมมา แต่เป็นการให้คำตอบแบบ “จับใจความ” สรุป และเรียบเรียงออกมาอย่างเป็นขั้นตอน
ติดตามเพจ Facebook : Thairath Money ได้ที่ลิงก์นี้ - https://www.facebook.com/ThairathMoney